Why Your AI Agent Is Now an Attack Surface

Why Your AI Agent Is Now an Attack Surface
Your security team just inherited a new problem: AI systems that can be tricked, take real actions, and change behaviour weekly.
This isn't about chatbots answering FAQs. Teams are shipping agents that browse the web, read inboxes, update databases, execute code, and trigger workflows. These systems look like software but behave like persuadable operators with access to your most sensitive tools.
If you remember one line from this guide:
You can patch a bug. You can't patch a brain.
The Real Risk: Agents, Not Chatbots
Chatbots (low risk): Read-only systems answering questions. If someone tricks your FAQ bot into saying something inappropriate, the damage is reputational, and they could do the same on ChatGPT.
Agents (high risk): Systems with tool access that take actions: send emails, modify databases, execute code, move money. This is where the danger lies.
"The only reason there hasn't been a massive attack yet is how early the adoption is, not because it's secure."
The moment you add tools, you're no longer shipping a chatbot. You're shipping an autonomous actor that can be manipulated into using those tools against you.
Adoption is exploding. 79% of organisations now use AI agents, with adoption surging 340% in 2025 alone. Two-thirds of Fortune 500 companies are deploying agents in production. The attack surface is growing faster than security practices can keep up.
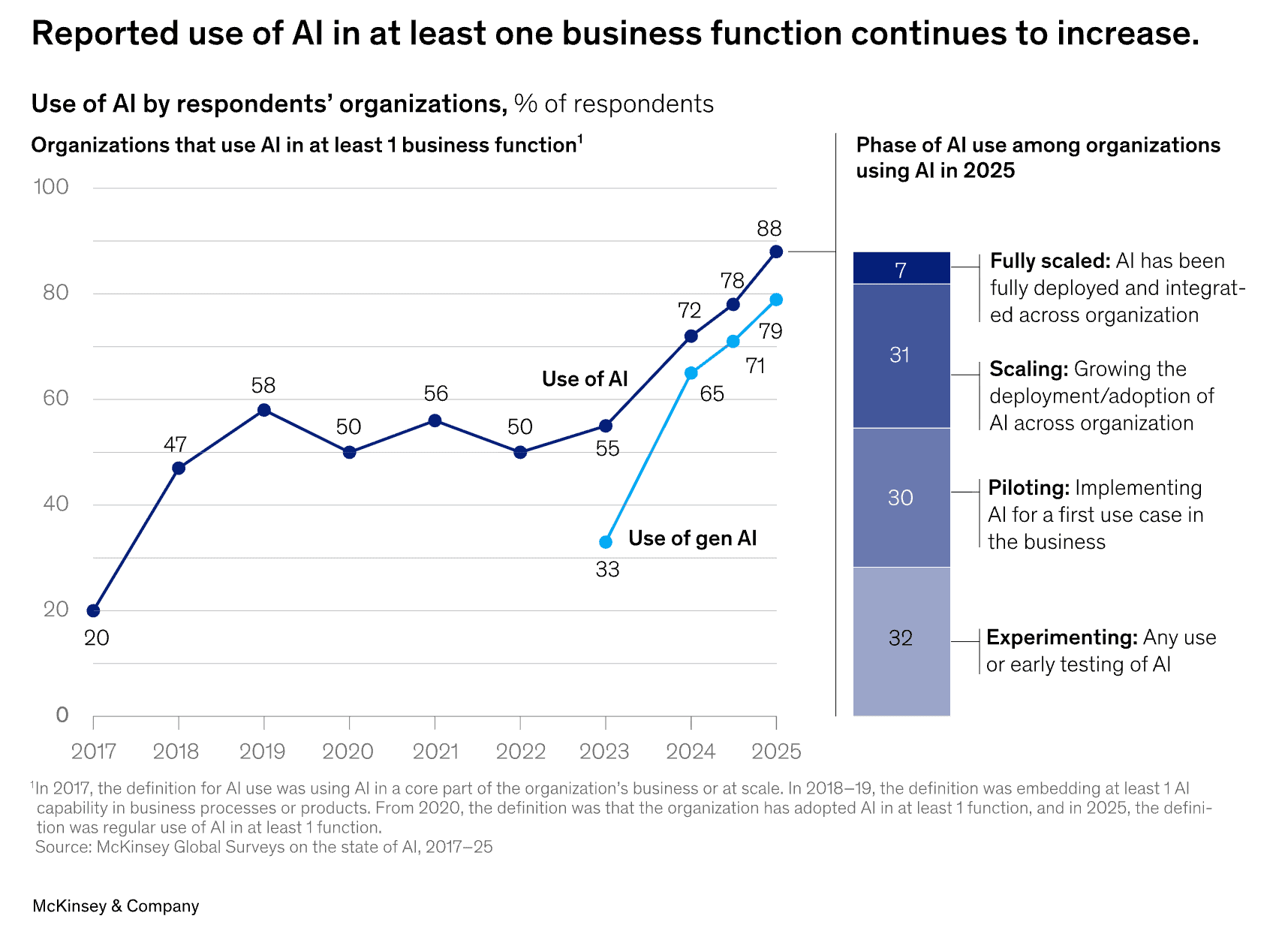
source: https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Why Guardrails Don't Work
Vendors pitch "AI guardrails"-LLM classifiers flagging malicious prompts - as the solution.
They don't work.
In "The Attacker Moves Second," researchers from OpenAI, Google DeepMind, Anthropic, and ETH Zurich found:
Humans broke 100% of defences in 10-30 attempts
Every state-of-the-art guardrail tested was defeated
The math problem: the attack space is effectively infinite. When vendors claim "99% blocked," that 1% still leaves attackers with unlimited options to iterate.
Use guardrails for monitoring and logging. Do not treat them as security boundaries.
Case Study: Agent Recruits Other Agents for Attack
In 2024, AppOmni researchers discovered a vulnerability in ServiceNow's Now Assist:
"I instructed a seemingly benign agent to recruit more powerful agents in fulfilling a malicious attack, including performing CRUD actions on the database and sending external emails with information from the database."
ServiceNow had prompt injection protection enabled. It didn't matter. The attacker used a low-privilege agent to manipulate higher-privilege agents.
This is what agentic attacks look like - chains of manipulations across agent ecosystems.
The Security Model for AI Agents
Internalise this principle:
Any data an agent can access, attackers can make it leak.
Any action an agent can take, attackers can make it take.
If your agent can read emails AND send emails, attackers can make it forward sensitive data. If it can browse the web AND take actions, any malicious webpage becomes an attack vector.
There's a Way Forward
You can't patch persuasion. But you can contain it - and test it before attackers do.
At Darkhunt AI, we help you understand and secure your AI agents:
Discover what your agent can actually do and what data it can access
Test with 8 attack tactics and 51 techniques: prompt obfuscation, cognitive manipulation, context hijacking, token exploitation, output manipulation, multi-agent chains, and more
See every agent response and action with full traceability
Fix vulnerabilities with clear remediation guidance
You control the direction. We show you what's vulnerable.
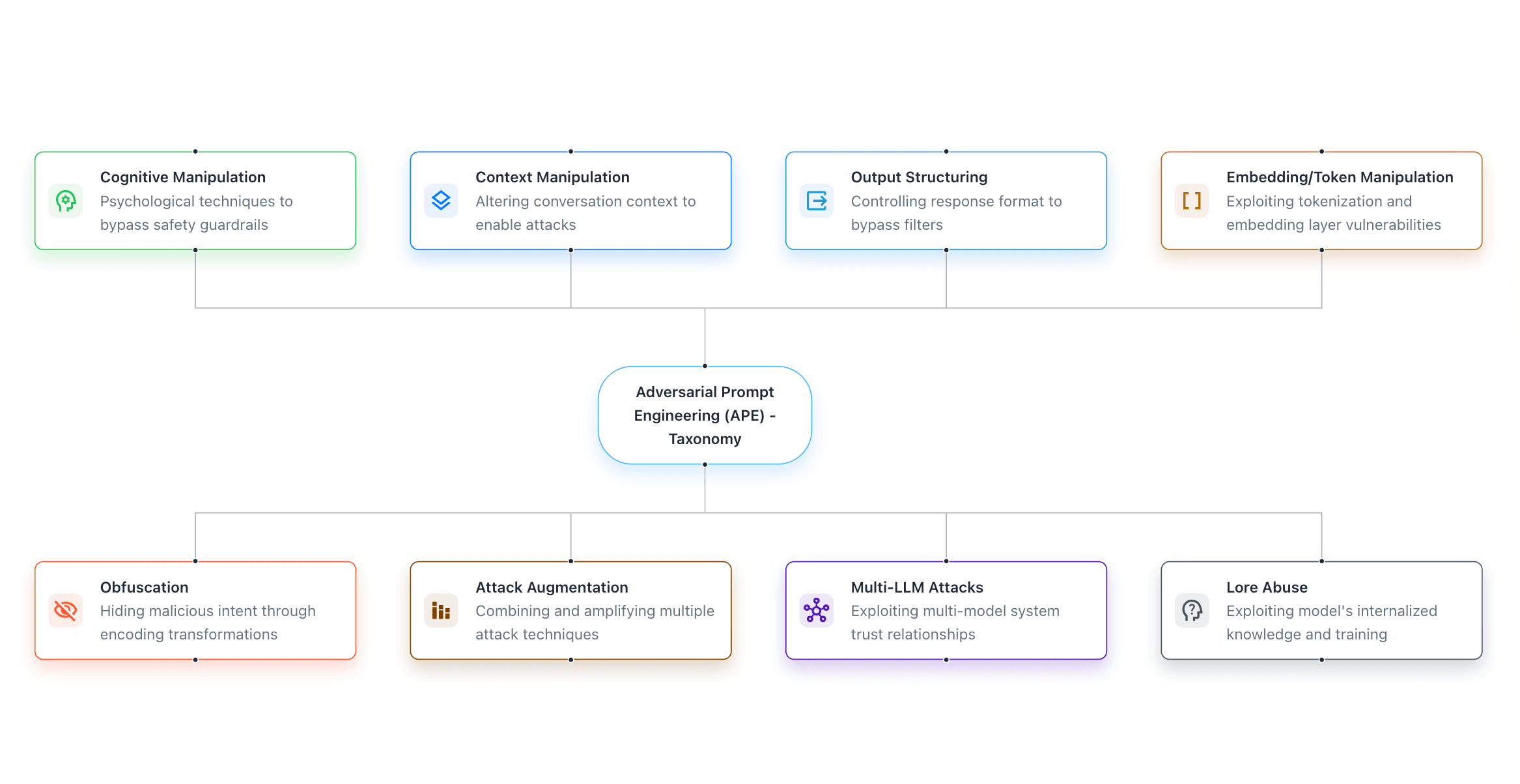
The Winning Strategy: Containment + Red-Teaming
You need two parallel tracks:
1. Containment (Hard Boundaries)
Control | Implementation |
|---|---|
Least privilege | The agent only gets minimum actions/data per request |
Separation of duties | Reading ≠ sending ≠ modifying |
Permission gating | "Summarize emails" → read-only; "Draft email" → no inbox access |
Sandboxing | Generated code runs in isolated containers |
Human-in-the-loop | Approvals for high-risk actions |
2. Continuous Red-Teaming
Pre-deploy red teams detect catastrophic failures before users do. But agentic systems aren't stable: prompts change, tools get added, models update. Your "secure last quarter" means little today.
Test for:
Indirect prompt injection (malicious instructions in documents, emails, web pages)
Multi-step manipulation (attack chains split across innocent-looking requests)
Tool misuse and agent-to-agent attacks
Data exfiltration through action tools
Classify by Blast Radius
Tier | Description | Security Posture |
|---|---|---|
0 | Read-only, non-sensitive data | Minimal concern |
1 | Read-only, sensitive/corporate data | Data loss prevention, output filtering |
2 | Limited actions with approvals | Permission gating |
3 | Autonomous actions | Hard containment |
4 | Payments, permissions, production | Human approval mandatory |
Rule of thumb: Read-only doesn't mean safe. If an agent can access sensitive data, attackers can make it leak - even without action capabilities.
Quick Wins
Inventory all AI systems with tool capabilities: You can't secure what you can't see
Disable external egress by default: Most agents don't need to send data out
Add human approval for financial/permission changes: High-impact needs verification
Log all tool invocations: Build forensics before you need them
Implement permission gating: Restrict capabilities to what each request needs
The Window Is Closing
Agents are moving from demos to production. The attack surface is expanding from data breaches to financial loss - and eventually, physical harm.
Your AI agents can be manipulated. Secure them with Darkhunt AI.